- Published on
queryKey 관리에 대한 고민 기록지 (with. Query Key Factory)
React Query를 사용해 Get 메서드로 데이터를 페칭하고 캐시 하는 작업을 진행하다 보면 queryKey가 필요하다. 기존 프로젝트에서는 queryKey를 따로 관리하지 않았다. 각자 프로젝트 내에서 다른 도메인을 작업하고 있었고, 개수 또한 적었기 때문이다. 따라서 내가 리뷰 페이지 작업을 진행하고 있다면 reviews라는 key를 지정해 사용한 기억만 있으면 됐다. 하지만, 프로젝트가 진행될수록 자연스럽게 queryKey의 개수도 많아졌고 기능을 병합하며 문제가 발생하기 시작했다.

협업, 유지/보수 측면에서 queryKey 관리 방법을 개선할 필요가 있다. 🧐
⚙️ 프로젝트 환경
Next.js 14TanStack/Query v5Tailwind CSS
🔍 문제 정의
- 동료 개발자와 queryKey 공유를 위해서는 직접 key를 설정한 hook을 확인하거나 직접 물어봐야 하는 불필요한 과정이 발생한다.
- queryKey 변경 시 다른 hook에 위치한 모든 key 값을 일일이 변경해 줘야 한다.
- queryKey 네이밍에 대한 고민 + 하드 코딩 과정에서 잘못된(오타, 중복) 값을 입력할 확률이 있다.
🤔 어떻게 개선할 것인가?
프런트엔드 팀원과는 이미 예전 회의 때부터 queryKey 관리에 대한 방안을 고민하고 있었기 때문에 곧바로 관련 Reference를 조사하고 도입을 준비했다.
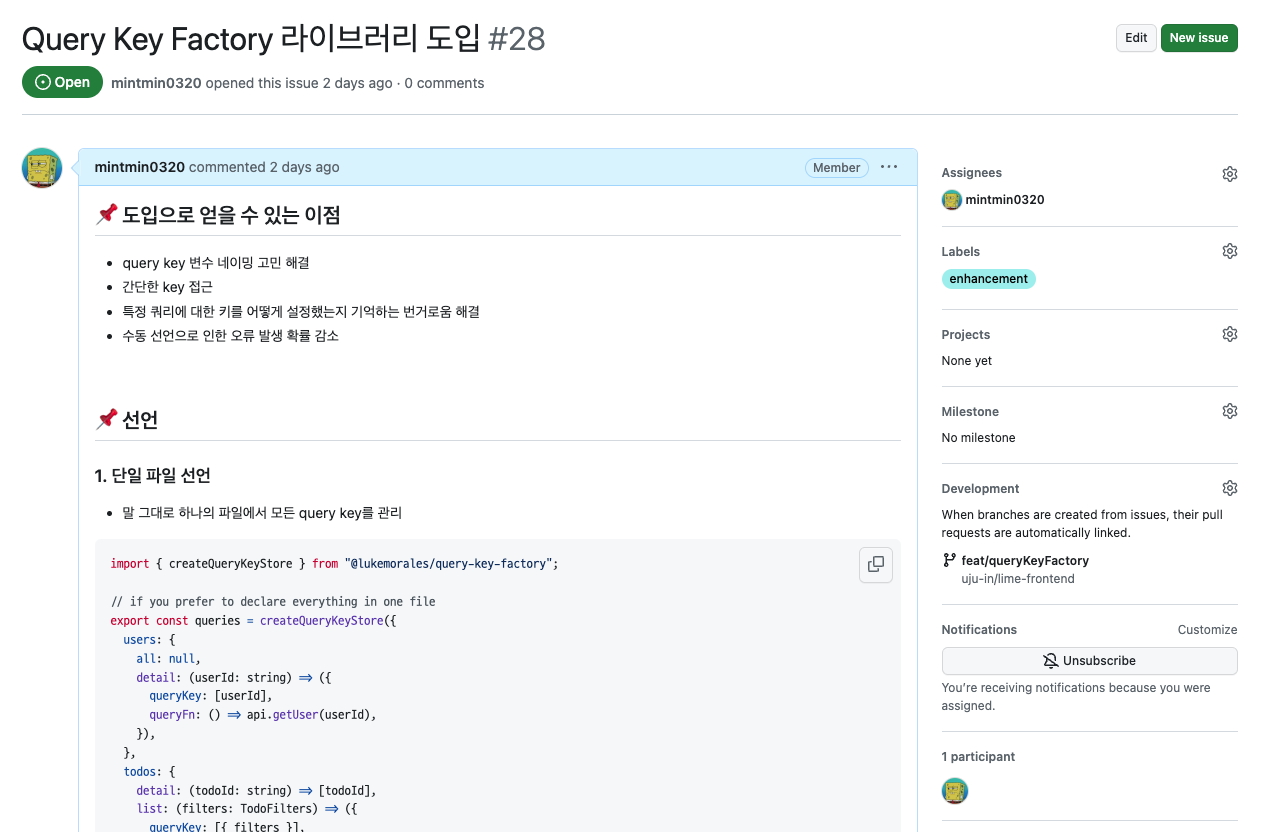
그러던 중 우연히 youtube 추천 영상에 뜬 프론트엔드 상태관리 실전 편 with React Query & Zustand 우아콘 발표 영상을 보게 되었다. 배달의 민족 개발자분들도 우리 팀과 비슷한 고민을 이미 하셨고 이를 해결하기 위해 라이브러리를 도입했다고 한다.
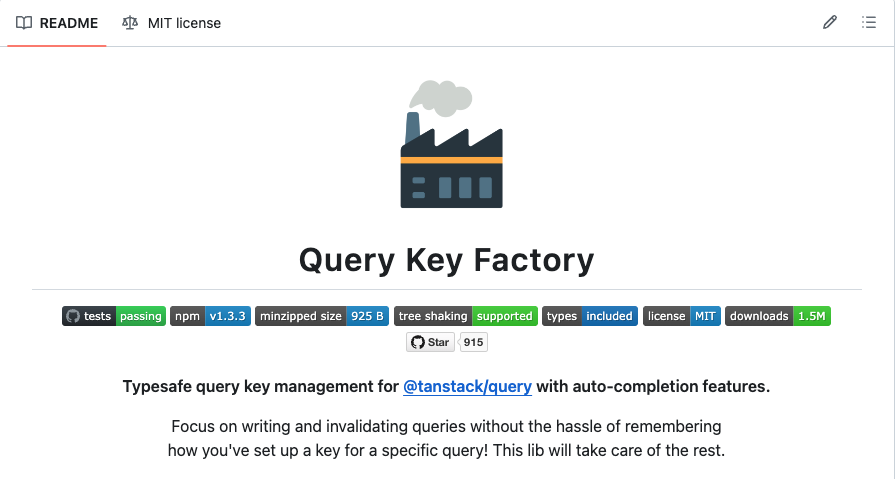
라이브러리명은 @lukemorales/query-key-factory로 처음 들었을 때 lukemorales가 무슨 의미일지 궁금했는데, 라이브러리 관리자님의 GitHub Id 혹은 성함인 것 같다. 😅
📌 앞으로 이 글에서는 @lukemorales/query-key-factory 라이브러리 외에는 언급할 일이 없기 때문에 편의상 라이브러리라고 지칭하겠다.
라이브러리 관련 Reference를 찾아보던 중 인상 깊었던 부분은 TanStack/query 공식 문서에서도 해당 내용을 명시하고 있다는 것이다.
QueryKeyFactory는 라이브러리명으로 사용되고 있어 라이브러리에서 제공하는 특수한 기능이라고 생각할 수도 있지만 queryKey를 효율적으로 관리하기 위한 패턴 혹은 구조라고 이해하면 될 것 같다.
그렇기 때문에 QueryKeyFactory 구조는 라이브러리 없이도 구현이 가능하다 라이브러리를 사용하면 QueryKeyFactory 구조를 좀 더 편하게 구현하고 사용할 수 있도록 하는 기능을 제공한다.
💡 고민 - 라이브러리.. 꼭 도입해야 할까?
앞서 언급했듯, 라이브러리 없이도 QueryKeyFactory 구조를 구현할 수 있다. 처음 관련 문서를 읽었을 때는 라이브러리를 굳이 적용해야 할지 의문이 들었다. 그래서 두 가지 방법을 모두 진행해 보고 차이점을 비교해 보자.
라이브러리를 적용한 예시 코드
/* 라이브러리 적용 ⭕️ */
export const reviewKeys = createQueryKeys('reviews', {
reviewList: (itemId: number, sortOption: SortOption) => [
itemId,
sortOption,
],
})
라이브러리 없이 QueryKeyFactory를 직접 구현한 예시 코드
/* 라이브러리 적용 ❌ */
export const reviewKeys = {
all: ['reviews'] as const,
reviewList: (itemId: number, sortOption: SortOption) => [
...reviewKeys.all, 'list', itemId, sortOption
] as const,
}
라이브러리를 적용하지 않는다고 해서 사용하는 데 있어서 큰 문제가 발생하지 않고 잘 작동한다. 또한 적용하지 않은 형태가 가독성이 떨어져 구조를 파악하는 데 있어서 어려움이 있다고도 느껴지지 않는다. 따라서 적용 여부를 결정할 때는 우선 새로 도입할 라이브러리의 장점을 파악할 필요성이 있다.
🤔 라이브러리 적용 시 얻을 수 있는 장점
1. 간결한 코드 작성
직접 구현할 경우 reviews라는 메인 키워드를 각 메서드마다 배열 병합을 진행하게 된다. 반면에 라이브러리를 적용 시 createQueryKeys 함수에 첫 번째 인자로 키워드를 설정해 보다 간편한 코드 작성이 가능하다.
2. queryKey 구조에 대한 명확한 파악
/* 라이브러리 적용 ⭕️ */
export const reviewKeys = createQueryKeys('reviews', {
reviewList: (itemId: number, sortOption: SortOption) => [ ⭐️
itemId,
sortOption,
],
})
reviewList queryKey는 reviews, reviewList 외에도 itemId, sortOption이라는 추가적인 요소를 가지게 된다. 위와같이 명시하므로써 더 명확하게 구조를 파악하는데 용이하다.
3. queryKey 네이밍 소요 감소
/* 라이브러리 적용 ❌ */
export const reviewKeys = {
all: ['reviews'] as const,
reviewList: (itemId: number, sortOption: SortOption) => [
...reviewKeys.all, 'list', itemId, sortOption
] as const,
}
reviewList 메서드를 살펴보면 'list'라는 키워드를 확인할 수 있다. 사용 의도는 크게 두 가지이다.
A. react-query-devtools에서 직관적인 queryKey 확인을 위해
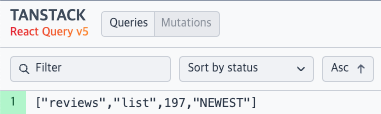
B. 메서드가 추가될 경우 구분을 위해
- itemId 같은 추가적인 매개변수가 없다면
...reviewKeys.all즉,reviews로queryKey가 중복된다.
이 과정에서 메서드명 reviewList에 더해 분류를 위한 키워드 네이밍을 해야 하는 소요가 발생하게 된다. 사실 처음에는 직접 구현을 결심했지만, 이 부분에서 결정적으로 라이브러리 적용으로 마음이 변하게 되었다.
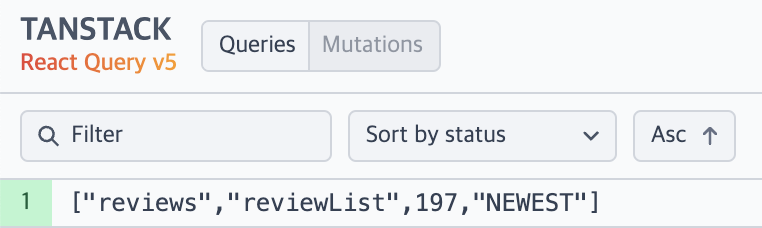
라이브러리를 적용하면, 메서드명이 반영되기 때문에 굳이 새로운 키워드를 추가할 필요가 없다.
👨🏻💻 실제 프로젝트에 적용해 보기
export const useSearchItemQuery = (
itemId: number,
sortOption: SortOption,
accessToken: string,
) => {
const { ... } =
useSuspenseInfiniteQuery({
queryKey: reviewKeys.reviewList( ⭐️
itemId, sortOption
).queryKey,
queryFn: ({ pageParam = null }) =>
fetchReviewList({
pageParam, itemId, sortOption, accessToken
}),
initialPageParam: null,
getNextPageParam: (lastPage: PagesResponse) => {
return lastPage.nextCursorId
},
staleTime: 1000 * 60,
})
...
}
- 자동완성으로 간편하고 정확하게 코드 작성이 가능하다.
queryKey 무효화 - queryClient.invalidateQueries
export default function useReviewLikeAction() {
const queryClient = useQueryClient()
return useMutation<void, Error, ReviewLikeRequest>({
mutationFn: ({ reviewId, isLiked }) =>
postReviewLikeAction({ reviewId, isLiked }),
onSuccess: () => {
alert('성공!')
queryClient.invalidateQueries({ ⭐️
queryKey: reviewKeys.reviewList._def
})
},
onError: (error) => {
alert(error)
},
})
}
처음 작성한 queryKey를 무효화하기 위해 QueryKeyFactory 구조에서 메서드를 호출했으나, 인자로 전달할 데이터(itemId, sortOption 등등)가 이 hook에는 없었기 때문에 어떻게 처리해야 될지 고민이 많았다.
그러던 중에 console.log()를 사용해 값을 확인해 본 결과 알고 보니 ._def를 사용하면 reviewList 메서드에 해당하는 queryKey를 손쉽게 호출할 수 있었다.
💡 추가적인 고민 - Next 캐시를 관리하는 tag 관리
export async function fetchItemDetail(itemId: number) {
const res = await fetch(
`${process.env.NEXT_PUBLIC_BASE_URL}/api/items/${itemId}`,
{
method: 'GET',
headers: {
'Content-Type': 'application/json',
},
next: { tags: ["itemDetail"] }, ⭐️
},
)
const data = await res.json()
if (!res.ok) {
throw data.message
}
return data
}
현재 우리 프런트엔드 팀은 무한 스크롤이나 React-Query가 필요한 상황이 아니라면 비동기 서버 컴포넌트를 활용해 데이터를 페칭하고 있다. 이 과정에서 캐시를 관리하는 key 역할을 수행하는 tag를 어떻게 관리해야 할지에 대한 많은 고민이 생겼다.
일단 QueryKeyFactory 구조에 적용하기에는 적용하는 형태가 조금 다르다. tags에 배열 형태로 값을 넣는 것도 불가능하고 그렇다고 문자열을 반환하게 한 뒤에 queryKey와 관리하기에는 비슷하지만 다른 역할을 수행하기에 따로 관리하는 것으로 결론을 내렸다.
예시 코드
import { createQueryKeys } from '@lukemorales/query-key-factory'
// React-Query queryKeys
export const itemKeys = createQueryKeys('items', {
itemList: (keyword: string, sortOption: string) => [keyword, sortOption],
})
// Next cache tags
export const itemTags = {
itemDetail: 'itemDetail' as const,
}
마치며
직전 프로젝트에서도 객체 형태로 queryKey를 관리했던 경험이 있었기 때문에 굳이 라이브러리를 적용해야 하는지에 대한 의구심이 많이 들었지만, 이번에 직접 적용해 보며 많은 장점이 있다는 것을 몸소 깨달을 수 있었다.
다만, 참고 자료가 많이 없기 때문에 생각보다 쉽지만은 않았다. 가이드와 비슷한 문서가 있지만, 사용방법 정도만 간단하게 나열되어 있기 때문에 코드 구조를 이해하는 데 있어 시간이 좀 필요했다. 그리고 QueryKeyFactory 구조 적용 시에 queryFn까지 같이 처리하는 경우가 많았는데, 개인적으로 "굳이?"라는 생각이 들었다. queryKey 관리가 주 목적이라고 생각했기 때문에 queryKey 관리에만 집중하면 된다고 생각했기 때문이다.
조금 아쉬운 부분이 있다면, Next tags를 조금 더 효율적으로 관리하는 방법과 queryKey와 조화시켜 사용하는 방법에 대한 부분이 아쉬움으로 남아있다. 이 부분은 앞으로 사용해 보며 느끼는 경험과 참고 자료를 조사해 수정해 나갈 필요성이 있다.